
Memorising = overfitting.
Large neural networks are tendent to overfit. And that is to be avoided.
Trade off between model and data
Regularization: to change data in a way that aids in avoiding overfitting.
flatten can be used on data that is flattend, but is not necesary.
When overfitting, it is because it has the capcit to fit disturbance patterns in the data (which is random noice). It will make the model perform worse.
The simplest way to avoid overfitting is to se a simple model. It can still happen, but there is less options to do so.
Large models have the potential to perform better when not overfitted.
Validation data as tool to detect overfitting
Vanishing gradient leads to weights of zero and small results.
Exploding gradient leads to infinite weights and large results.
Early stopping is stopping the model when it’s posible to tell that the model started stagnate.
Weight regulariztion as tool to improve generalization
Weight is hard to regularize, as it can only be optimized through trial and error.
Weight reularization can be done with weight. This is done by shinkage. Weights for poor classifiers are set to 0.
Weight regulariation can be done with l1 and l2.
Weight initialization can also be uses. Which is to adjust weights before training start.
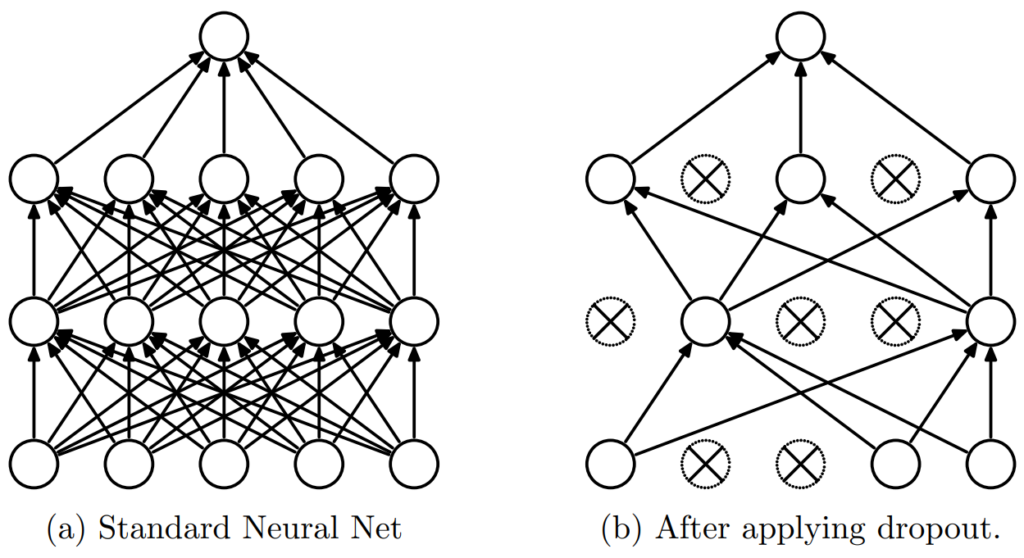
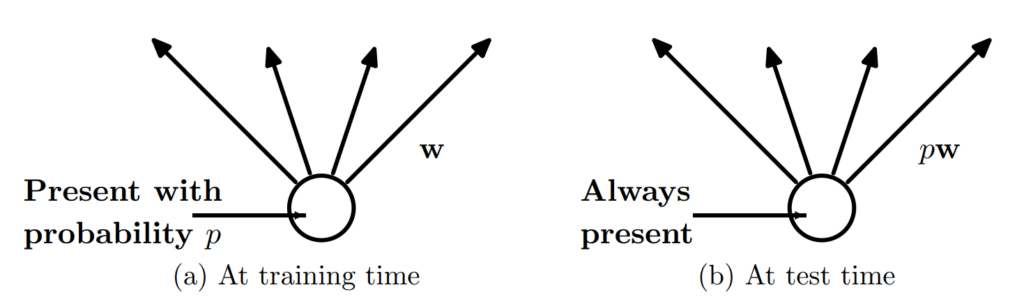
Dropout as tool to improve generalization
Dropout can be used to reguralize by removing some connections at a given layer. It introduces noice and limits the potential of hidden nodes to co-addapt.
Batch normalization as tool to improve training and generalization
Batch normalization is good to implement before dropout. This will be discoused later.
Normalizing can help not only at the input layer, but at every layer. Batch normalizion is an option to do that.
It does have some drawbacks. It reqires a slow learning rate, carefull initialization and it may saturate non-linearties by making gradients.

γ and B (the betta) introduces bias, but since they are trainable, they can be optimized. Ecentialy noice is introduced only to be further reduced.
Batch normalization is allmost allways a good idea.
Small batch sizes don’t allways work so well – especially batch sizes of 1. To large batch sizes might introduce other problems too.
It does require somewhat high computeational power.
Batch normilization works well with other methods of normilization. Usually dropout.
Data augmentation
With a set of data, eg. images, especially a small sample, the data can be transormed in some degree to be computated as new data.
This could be done by rotating, asdjusting colors, fliping and introduce noice to the pictures.
Augmentation will add a lot more data to the dataset.